Big Data - Map Reduce & NoSQL

Nama : Hadi Daryanto
Kelas :
4IA17
NPM
: 53410073
1. PENDAHULUAN
1.1 Latar
belakang
Akhir-akhir
ini, istilah ‘big data’ menjadi topik yang dominan dan sangat sering dibahas
dalam industri IT. Banyak pihak yang mungkin heran kenapa topik ini baru
menjadi pusat perhatian padahal ledakan informasi telah terjadi secara
berkelangsungan sejak dimulainya era informasi. Perkembangan volume dan jenis
data yang terus meningkat secara berlipat-lipat dalam dunia maya Internet
semenjak kelahirannya adalah fakta yang tak dapat dipungkiri. Mulai data yang
hanya berupa teks, gambar atau foto, lalu data berupa video hingga data yang
berasal system pengindraan. Lalu kenapa baru sekarang orang ramai-ramai
membahas istilah big data? Apa sebenarnya ‘big data’ itu?
Hingga saat ini, definisi resmi dari istilah big data belum ada.
Namun demikian, latar belakang dari munculnya istilah ini adalah fakta yang
menunjukkan bahwa pertumbuhan data yang terus berlipat ganda dari waktu ke
waktu telah melampaui batas kemampuan media penyimpanan maupun sistem database
yang ada saat ini. Kemudian, McKinseyGlobal Institute (MGI), dalam laporannya
yang dirilis pada Mei 2011, mendefinisikan bahwa big data adalah data yang
sudah sangat sulit untuk dikoleksi, disimpan, dikelola maupun dianalisa dengan
menggunakan sistem database biasa karena volumenya yang terus berlipat. Tentu
saja definisi ini masih sangat relatif, tidak mendeskripsikan secara eksplisit
sebesar apa big data itu. Tetapi, untuk saat sekarang ini, data dengan volume
puluhan terabyte hingga beberapa petabyte kelihatannya dapat memenuhi definis
MGI tersebut. Di lain pihak, berdasarkan definisi dari Gartner, big data itu memiliki tiga atribute yaitu :
volume , variety , dan velocity. Ketiga atribute ini dipakai juga oleh IBM dalam mendifinisikan big data. Volume berkaitan
dengan ukuran, dalam hal ini kurang lebih sama dengan definisi dari MGI.
Sedangkan variety berarti tipe atau jenis data, yang meliputi berbagai jenis
data baik data yang telah terstruktur dalam suatu database maupun data yang
tidak terorganisir dalam suatu database seperti halnya data teks pada web
pages, data suara, video, click stream, log file dan lain sebagainya. Yang
terakhir, velocity dapat diartikan sebagai kecepatan dihasilkannya suatu data
dan seberapa cepat data itu harus diproses agar dapat memenuhi permintaan
pengguna.
1.2 Tujuan
Tujuan dari penulisan ini diharapkan dapat mengetahui apa itu Big Data, Map
Reduce & NoSQL dan di manfaatkan untuk mempermudah manusia dalam melakukan
pekerjaan dibidang apapun.
2. ISI
PENJELASAN
Definisi Big Data
Jika diterjemahkan secara mentah-mentah maka Big
Data berarti suatu data dengan kapasitas yang besar. Sebagai
contoh, saat ini kapasitas DWH yang digunakan oleh perusahaan-perusahaan di
Jepang berkisar dalam skala terabyte. Namun,
jika misalnya dalam suatu sistem terdapat 1000 terabyte (1 petabyte) data,
apakah sistem tersebut bisa disebut Big Data?
Satu lagi, Big Data sering
dikaitkan dengan SNS (Social Network Service),
contohnya Facebook. Memang
benar Facebook memiliki lebih dari 800 juta orang
anggota, dan dikatakan bahwa dalam satu hari Facebook memproses
sekitar 10 terabyte data.
Pada umumnya, SNS seperti Facebook tidak
menggunakan RDBMS(Relational DataBase Management
System) sebagai software pengolah data, melainkan lebih banyak
menggunakan NoSQL. Lalu, apa kita bisa menyebut sistem NoSQL sebagaiBig
Data?
Dengan mengkombinasikan kedua uraian diatas, dapat ditarik
sebuah definisi bahwa Big Data adalah
“suatu sistem yang menggunakan NoSQL dalam memproses atau mengolah data yang
berukuran sangat besar, misalnya dalam skala petabyte“. Apakah
definisi ini tepat? Boleh dikatakan masih setengah benar. Definisi tersebut
masih belum menggambarkan Big Data secara
menyeluruh. Big Datatidak
sesederhana itu,
Big Data memuat arti yang lebih kompleks sehingga perlu definisi yang
sedikit lebih kompleks pula demi mendeskripsikannya secara keseluruhan.
Mengapa butuh definisi yang lebih kompleks? Fakta menunjukkan
bahwa bukan hanya NoSQL saja yang mampu mengolah data dalam skala raksasa (petabyte).
Beberapa perusahaan telah menggunakan RDBMS untuk memberdayakan data dalam
kapasitas yang sangat besar. Sebagai contoh, Bank of America memiliki
DWH dengan kapasitas lebih dari 1,5 petabyte, Wallmart
Stores yang bergerak dalam bisnis retail (supermarket)
berskala dunia telah mengelola data berkapasitas lebih dari 2,5 petabyte,
dan bahkan situs auction (lelang) eBay memiliki
DWH yang menyimpan lebih dari 6petabyte data.
Oleh karena itu, hanya karena telah berskala petabyte saja,
suatu data belum bisa disebut Big Data. Sekedar
referensi, DWH dengan kapasitas sangat besar seperti beberapa contoh diatas
disebut EDW(Enterprise Data Warehouse)
dan database yang digunakannya disebut VLDB(Very Large Database).
Memang benar, NoSQL dikenal memiliki potensi dan kapabilitas Scale
Up (peningkatan kemampuan mengolah data dengan menambah jumlah server atau storage)
yang lebih unggul daripada RDBMS. Tetapi, bukan berarti RDBMS tak diperlukan.
NoSQL memang lebih tepat untuk mengolah data yang sifatnya tak berstruktur
seperti data teks dan gambar, namun NoSQL kurang tepat bila digunakan untuk
mengolah data yang sifatnya berstruktur seperti data-data numerik, juga kurang
sesuai untuk memproses data secara lebih detail demi menghasilkan akurasi yang
tinggi. Pada kenyataannya, Facebook juga tak hanya menggunakan NoSQL untuk
memproses data-datanya, Facebook juga tetap menggunakan RDBMS. Lain kata,
penggunaan RDBMS dan NoSQL mesti disesuaikan dengan jenis data yang hendak
diproses dan proses macam apa yang dibutuhkan guna mendapat hasil yang optimal.
Gambar Big Data Infographic sumber intel.co.jp
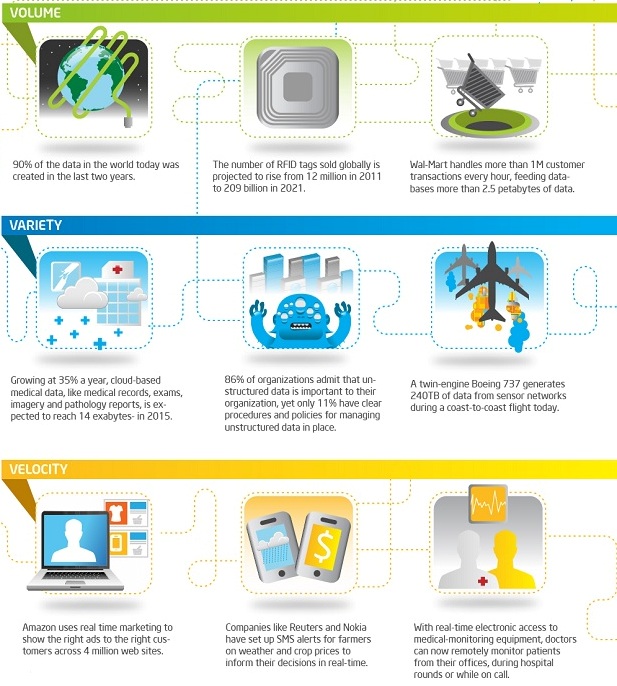
Karakteristik Big Data : Volume, Variety, Velocity (3V)
Kembali ke pertanyaan awal, apakah sebenarnya Big Data itu?
Sayang sekali, hingga saat ini masih belum ada definisi baku yang disepakati
secara umum. Ada yang mendeskripsikan Big Data sebagai
fenomena yang lahir dari meluasnya penggunaan internet dan kemajuan teknologi
informasi yang diikuti dengan terjadinya pertumbuhan data yang luar biasa
cepat, yang dikenal dengan istilah ledakan informasi (Information
Explosion) maupun banjir data (Data Deluge). Hal
ini mengakibatkan terbentuknya aliran data yang super besar dan terus-menerus
sehingga sangat sulit untuk dikelola, diproses, maupun dianalisa dengan
menggunakan teknologi pengolahan data yang selama ini digunakan (RDBMS).
Definisi ini dipertegas lagi dengan menyebutkan bahwa Big
Data memiliki tiga karakteristik yang dikenal dengan istilah
3V: Volume, Variety, Velocity. Dalam hal ini, Volumemenggambarkan
ukuran yang superbesar, Variety menggambarkan
jenis yang sangat beragam, danVelocity menggambarkan
laju pertumbuhan maupun perubahannya. Namun demikian, definisi ini tentu masih
sulit untuk dipahami. Oleh karena itu, uraian berikut mencoba memberikan
gambaran yang lebih jelas dan nyata berkaitan dengan maksud definisi Big
Data tersebut.

Gambar karakteristik big data
Bukan Hanya Masalah Ukuran,
Tapi Lebih pada Ragam
Kini jelas bahwa Big Data bukan
hanya masalah ukuran yang besar, terlebih yang menjadi ciri khasnya adalah
jenis datanya yang sangat beragam dan laju pertumbuhan maupun frekwensi
perubahannya yang tinggi. Dalam hal ragam data, Big
Data tidak hanya terdiri dari data berstruktur seperti halnya
data angka-angka maupun deretan huruf-huruf yang berasal dari sistem database
mendasar seperti halnya sistem database keuangan, tetapi juga terdiri atas data
multimedia seperti data teks, data suara dan video yang dikenal dengan istilah
data tak berstruktur. Terlebih lagi, Big Data juga
mencakup data setengah berstruktur seperti halnya data e-mail maupun XML. Dalam
hal kecepatan pertumbuhan maupun frekwensi perubahannya, Big
Data mencakup data-data yang berasal dari berbagai jenis
sensor, mesin-mesin, maupun data log komunikasi yang terus menerus mengalir.
Bahkan, juga mencakup data-data yang tak hanya data yang berada di internal
perusahaan, tetapi juga data-data di luar perusahaan seperti data-data di
Internet. Begitu beragamnya jenis data yang dicakup dalam Big
Data inilah yang kiranya dapat dijadikan patokan untuk membedakan Big
Data dengan sistem manajemen data pada umumnya.
Fokus pada Trend per-Individu, Kecepatan Lebih Utama daripada Ketepatan
Hingga saat ini, pendayagunaan Big Data didominasi
oleh perusahaan-perusahaan jasa berbasis Internet seperti halnya Google dan
Facebook. Data yang mereka berdayakan pun bukanlah data-data internal
perusahaan seperti halnya data-data penjualan maupun data pelanggan, lebih
menitik beratkan pada pengolahan data-data teks dan gambar yang berada di
Internet. Bila kita melihat gaya pemberdayaan data yang dilakukan oleh
perusahaan-perusahaan pada umumnya, yang dicari adalahtrend yang
didapat dari pengolahan data secara keseluruhan. Misalnya, dari data konsumen
akan didapat informasi tentang trend konsumen
dengan memproses data konsumen secara keseluruhan, bukan memproses data
per-konsumen untuk mendapatkan trend per-konsumen.
Dilain pihak, perusahaan-perusahaan jasa berbasis Internet yang memanfaatkan Big
Data justru memfokuskan pemberdayaan data untuk mendapatkan
informasi trend per-konsumen
dengan memanfaatkan atribut-atribut yang melekat pada pribadi tiap konsumen.
Sebut saja toko online Amazon yang memanfaatkan informasi maupun atribut yang
melekat pada diri per-konsumen, untuk memberikan rekomendasi yang sesuai kepada
tiap konsumen. Satu lagi, pemberdayaan data ala Big
Data ini dapat dikatakan lebih berfokus pada kecepatan
ketimbang ketepatan.
MapReduce
MapReduce adalah model pemrograman rilisan
Google yang ditujukan untuk memproses data berukuran raksasa secara
terdistribusi dan paralel dalam cluster yang terdiri atas ribuan komputer.
Dalam memproses data, secara garis besar MapReduce dapat dibagi dalam dua
proses yaitu proses Map dan proses Reduce. Kedua jenis proses ini
didistribusikan atau dibagi-bagikan ke setiap komputer dalam suatu cluster
(kelompok komputer yang salih terhubung) dan berjalan secara paralel tanpa
saling bergantung satu dengan yang lainnya. Proses Map bertugas untuk
mengumpulkan informasi dari potongan-potongan data yang terdistribusi dalam
tiap komputer dalam cluster. Hasilnya diserahkan kepada proses Reduce untuk
diproses lebih lanjut. Hasil proses Reduce merupakan hasil akhir yang dikirim
ke pengguna.
Dari definisinya, MapReduce mungkin
terkesan sangat ribet. Untuk memproses sebuah data raksasa, data itu harus
dipotong-potong kemudian dibagi-bagikan ke tiap komputer dalam suatu cluster.
Lalu proses Map dan proses Reduce pun harus dibagi-bagikan ke tiap komputer dan
dijalankan secara paralel. Terus hasil akhirnya juga disimpan secara
terdistribusi. Benar-benar terkesan merepotkan.
Beruntunglah, MapReduce telah didesain
sangat sederhana alias simple. Untuk menggunakan MapReduce, seorang programer
cukup membuat dua program yaitu program yang memuat kalkulasi atau prosedur
yang akan dilakukan oleh proses Map dan Reduce. Jadi tidak perlu pusing
memikirkan bagaimana memotong-motong data untuk dibagi-bagikan kepada tiap
komputer, dan memprosesnya secara paralel kemudian mengumpulkannya kembali.
Semua proses ini akan dikerjakan secara otomatis oleh MapReduce yang dijalankan
diatas Google File System

Gambar map and reduce Google file service
Program yang memuat kalkulasi yang akan dilakukan dalam proses
Map disebut Fungsi Map, dan yang memuat kalkulasi yang akan dikerjakan oleh
proses Reduce disebut Fungsi Reduce. Jadi, seorang programmer yang akan menjalankan
MapReduce harus membuat program Fungsi Map dan Fungsi Reduce. Fungsi Map
bertugas untuk membaca input dalam bentuk pasangan Key/Value, lalu menghasilkan
output berupa pasangan Key/Value juga. Pasangan Key/Value hasil fungsi Map ini
disebut pasangan Key/Value intermediate. Kemudian, fungsi Reduce akan membaca
pasangan Key/Value intermediate hasil fungsi Map, dan menggabungkan atau
mengelompokkannya berdasarkan Key tersebut. Lain katanya, tiap Value yang
memiliki Key yang sama akan digabungkan dalam satu kelompok. Fungsi Reduce juga
menghasilkan output berupa pasangan Key/Value. Untuk memperdalam pemahaman,
mari kita simak satu contoh. Taruhlah kita akan membuat program MapReduce untuk
menghitung jumlah tiap kata dalam beberapa file teks yang berukuran besar.Dalam program ini, fungsi Map dan fungsi
Reduce dapat didefinisikan sebagai berikut:
map(String key, String value):
//key : nama file teks.
//value: isi file teks tersebut.
for each word W in value:
emitIntermediate(W,”1″);
reduce(String key, Iterator values):
//key : sebuah kata.
//values : daftar yang berisi hasil
hitungan.
int result = 0;
for each v in values:
result+=ParseInt(v);
emit(AsString(result));
Hasil akhir dari program ini adalah
jumlah dari tiap kata yang terdapat dalam file teks yang dimasukkan sebagai
input program ini.
Gambar Menghitung jumlah tiap kata pada
dokumen

Dari segi teknologi, dipublikasikannya GoogleBigtable pada 2006 telah menjadi moment
muncul dan meluasnya kesadaran akan pentingnya kemampuan untuk memproses ‘big
data’. Berbagai layanan yang disediakan Google, yang melibatkan pengolahan data
dalam skala besar termasuk search engine-nya,
dapat beroperasi secara optimal berkat adanya Bigtable yang merupakan sistem
database berskala besar dan cepat. Semenjak itu, teknik akses dan penyimpanan
data KVS (Key-Value Store) dan teknik komputasi paralel yang disebutMapReduce mulai menyedot banyak perhatian. Lalu,
terinspirasi oleh konsep dalam GoogleFile System dan MapReduce yang menjadi pondasi
Google Bigtable, seorang karyawan Yahoo! bernama Doug Cutting kemudian
mengembangkan software untuk komputasi paralel terdistribusi (distributed
paralel computing) yang ditulis dengan menggunakan Java dan diberi nama Hadoop. Saat ini Hadoop telah menjadi project open
source-nya Apache Software. Salah satu pengguna Hadoop adalah
Facebook, SNS (Social Network Service) terbesar dunia dengan jumlah pengguna
yang mencapai 800 juta lebih. Facebook menggunakan Hadoop dalam memproses big
data seperti halnya content sharing, analisa access log, layanan message /
pesan dan layanan lainnya yang melibatkan pemrosesan big data.
3. Kesimpulan
Berdasar uraian diatas, dapat ditarik kesimpulan
bahwa yang dimaksud dengan ‘big data’ bukanlah semata-mata hanya soal ukuran,
bukan hanya tentang data yang berukuran raksasa. Big data adalah data berukuran
raksasa yang volumenya terus bertambah, terdiri dari berbagai jenis atau varietas
data, terbentuk secara terus menerus dengan kecepatan tertentu dan harus
diproses dengan kecepatan tertentu pula. Momen awal ketenaran istilah ‘big
data’ adalah kesuksesan Google dalam memberdayakan ‘big data’ dengan
menggunakan teknologi canggihnya yang disebut Bigtable beserta
teknologi-teknologi pendukungnya
4. Daftar Pustaka / Referensi :
Semoga
Bermanfaat…



